IBM PowerSystem agentless OS CPU Utilization

I was trying to understand the difference between CPU metrics in:
-LPAR2RRD and IBM CMC - Enterprise Pool 2.0
-IBM CMC - Capacity Monitoring
All 3 tools gather performance through the HMC APIs but Capacity Monitoring report always a lower CPU usage.
Looking at two real cases I assumed that LPAR2RRD report the CPU assigned by the hypervisor to the LPAR
(utilizedCapped+utilizedUncapped) while Capacity Monitoring reports only "utilized" processor unit defined on the HMC REST APIs docs as: utilizedCapped + utilizedUncapped - idle.
The difference is the CPU assigned to the LPAR but not used by the OS (idleProcessorUnits).
In some case the idleProcessroUnits is not a so small fraction of CPU reported by LPARD2RRD: it could be usefull gather and graph the utilizedProcUnits too.
For example in the following situation (IBM i LPAR, capped) when the CPU is capped to "9" you are inclined to think that system is slow. This is not true because there are a few idle core.
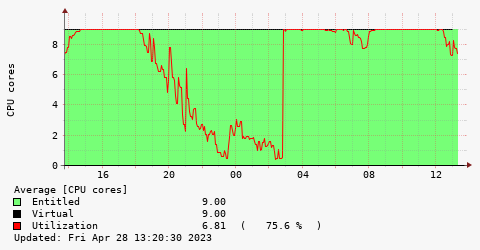
It could could be considered an agentless OS CPU utilization monitoring
Comments
-
Hi,
what we present is CPU allocation rather than real CPU utilisation which is always lower.
We take into consideration idle unly for CPU dedicated LPARs where it is only the way to get any CPU utilisation number.
Are you sure that CMC displays CPU utilisation ( allocation - idle)? I am quite surprised then, would not excpect it. Then it can allocate even more CPUs than is in the pool limit but when utilisation stays under limit then no sanctions? Hmm ...
What HMC itself reporting in graph? I belive same like we do it allocation.
BTW we are working on PEP2.0 support right now, it will be available in next version (June 2023)
-
CMC Capacity monitoring application it's not related to the EP2.0 and report CPU utilization (allocation - idle):

In the same interval LPAR2RRD reports CPU allocation as follow:
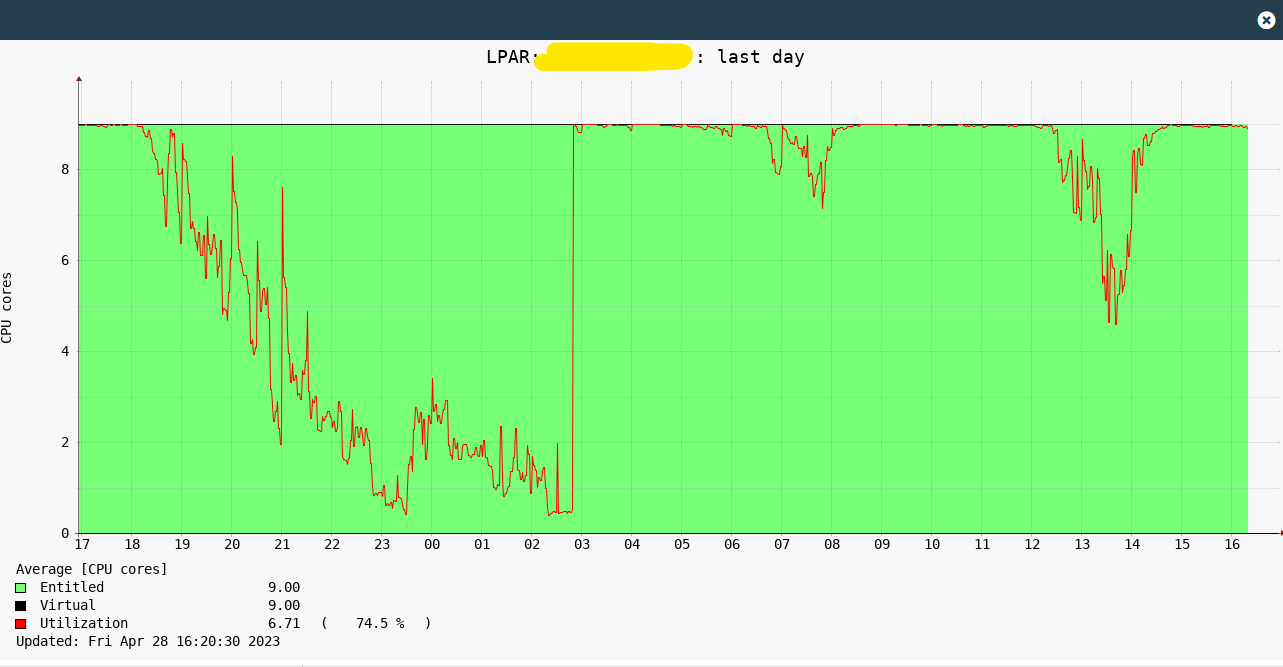
CMC Enterprice Pool 2.0 report the same value of LPAR2RRD (accounted for "pay per use" on the whole pool)
(we have only istantaneous value for each LPAR)

Overlapping the CMC capacity and the LPAR2RRD CPU usage/allocation can more clearly show the status of the system.
-
so they are 2 different things, I am right?
- CMC historical report uses allocation - idle
- CMC pool capacity monitoring uses allocation for checking if you reach the allocated limit
-
yes, you are right.
-
ok, then most important metrics in regards of CMC and its pools in terms of IBM payment for overcoming it is CPU allocation (no matter about idles) which we monitoring now. I am right?
On the other hand would be handy to have some other sets of graph called like CPU Utilisation (allocation - idle) for another admin view to the performance
BTW you can see already such vie when you have our OS agents in "CPU OS" graphs, but they are not aggregated per server ...
-
BTW any experience how CMC handles capacity allocated to CPU dedicated lpars?
Does it count all entitlement (allocation) or actual allocation - idle?
Any changes if CPU allocated lpar is in shared (can provide not used CPU cycles to the pool) or non shared CPU mode?
-
You're right: CPU cycles allocated to LPARs by the hypervisor are accounted for CPU usage in EP2.0.
If you go over the prepaid CPU cores available in the pool you enter in the "paid per use zone" (and you pay for idle cycles too.)
Moreover, idle cycles are not availbale for sharing with othe LPAR (having a lot of idle is not efficient)
It would be handy having "allocated" and "used" (allocated -idle) on the same graph (probably, at 100% of allocated CPU, you can still have good performance if there's a good portion of "idle")
OS Agent in "WRKACTJOB/CPUTOP" for IBM i does not report all the used CPU cycles (TOP n approach)
I do not have experience with dedicated LPARS and I cannot test it because my EP2.0 is not enabled for it. All of my LPARs and feeded infos are about LPAR in shared processor mode (capped or uncapped).
-
Hi,
I was talking about AIX/Linux/Solaris in terms of "CPU OS", we have no eqvivalent for IBM i without idle cycles.
Thanks for the ideas about the idle cycles, we will try to do something with that.

Howdy, Stranger!
Categories
- 1.7K All Categories
- 131 XorMon
- 26 XorMon Original
- 178 LPAR2RRD
- 14 VMware
- 20 IBM i
- 2 oVirt / RHV
- 5 MS Windows and Hyper-V
- Solaris / OracleVM
- 1 XenServer / Citrix
- Nutanix
- 8 Database
- 2 Cloud
- 10 Kubernetes / OpenShift / Docker
- 142 STOR2RRD
- 20 SAN
- 7 LAN
- 19 IBM
- 8 EMC
- 12 Hitachi
- 5 NetApp
- 17 HPE
- 1 Lenovo
- 1 Huawei
- 3 Dell
- Fujitsu
- 2 DataCore
- INFINIDAT
- 4 Pure Storage
- Oracle